Overview
“Mike 3.0” is the AI assistant living on this blog (You should see it on the right bottom corner!). Its job is to answer questions about me, my projects, and my website with high accuracy and a specific persona.
To build it, I conducted a head-to-head experiment between two dominant paradigms:
- RAG (Retrieval Augmented Generation): Give the model a library of my posts to read on demand.
- LoRA (Fine-Tuning): Train the model to memorize my posts and adopt my persona permanently.
This project was a deep dive into option #2, comparing it against the existing RAG implementation.
LoRA Tech Stack
| Technology | Description |
|---|---|
| gemma-3-12b-it | Base model for LoRA training. Google’s open weights model, fine-tuned to adopt a specific persona. |
| MLX | Efficient machine learning framework specifically optimized for Apple Silicon. |
| Ollama | Local runner used to serve the Teacher Model (Gemma 3 27B) for synthetic data generation. |
| Langflow | Visual orchestration tool used to build and test the chat interface. |
| uv | Fast Python package installer and resolver, used to manage dependencies and run scripts. |
High-Level Comparison (RAG vs LoRA)
| Feature | RAG | LoRA |
|---|---|---|
| Mechanism | Looks up answers in a database | Memorizes answers in weights |
| Knowledge Source | Dynamic Markdown Files | Static Training Dataset |
| Latency | Slower (Retrieval + Inference) | Fast (Inference Only) |
| Updates | Instant (File Save) | Slow (Re-training ~1hr) |
| Hallucinations | Low (Grounding Context) | Moderate (Memory Gaps) |
TL;DR
Final Pick: The RAG System
The RAG system is designed for freshness. It watches my Obsidian vault and portfolio directory for changes. When I write a new post, it is immediately chunked, embedded, and made available to the chatbot.
In terms of accuracy, it is the clear winner. It can answer questions about my projects, my resume, and my website with high accuracy likely because it retrieves the relevant source material and injects it directly into the context window, ensuring every answer is grounded in actual data rather than probabilistic memory.
Tech Stack:
- Orchestration: Python (FastAPI)
- Vector DB: PostgreSQL + pgvector
- Embedding:
text-embedding-gte-qwen2-1.5b-instruct - LLM:
google/gemma-3-12b
RAG Architecture
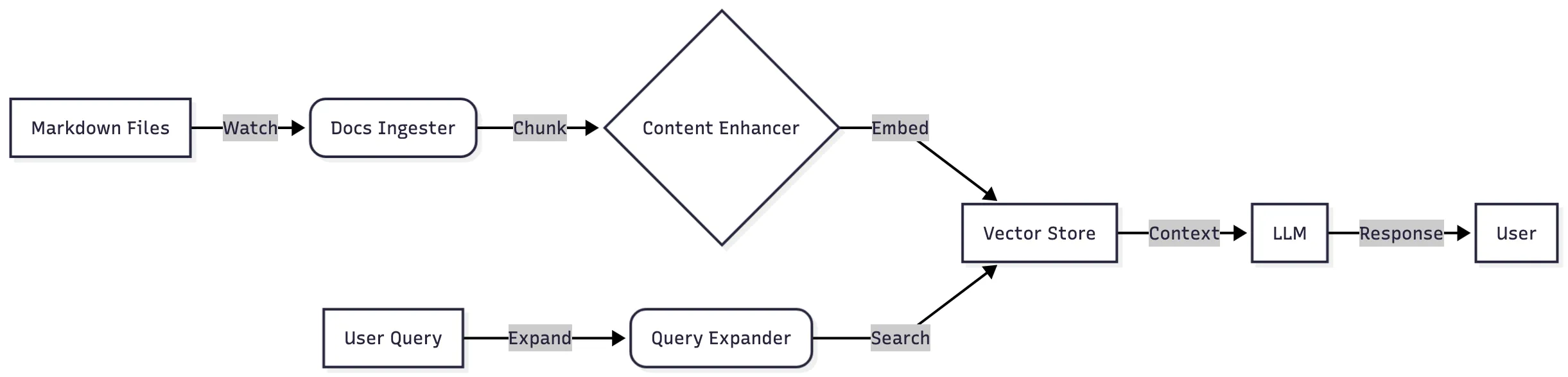
You can see the detailed post about the RAG system here.
Deep Dive: Building the LoRA
The LoRA model is designed for style. I wanted to see if a small model (12B) could essentially “become” me by reading everything I’ve ever written.
Tech Stack:
- Base Model:
google/gemma-3-12b-it - Framework: MLX (Apple Silicon optimized)
- Training Data: 701 Q&A pairs.
- Hardware: MacBook Pro M4 Max (Shared Memory).
1. Data Pipeline

A. Data Collection
I wrote a pipeline to convert my entire Astro content directory into a format Gemma could understand.
First, we gather the raw data using copy_data.py:
def copy_directory_contents(src_dir, dest_dir):
# ... (setup paths)
for file_path in src_path.rglob('*'):
if file_path.is_file() and file_path.suffix in ['.md', '.mdx']:
# Flatten directory structure for processing
shutil.copy2(file_path, target_path)copy_data.pycopy_data.pyB. Data Preprocessing
I processed the raw markdown files to create manageable chunks for training.
CHUNK_SIZE = 1000 # Characters
CHUNK_OVERLAP = 100
def chunk_text(text, chunk_size=CHUNK_SIZE, overlap=CHUNK_OVERLAP):
"""Splits text into overlapping chunks."""
if not text:
return []
chunks = []
start = 0
while start < len(text):
end = start + chunk_size
chunk = text[start:end]
chunks.append(chunk)
if end >= len(text):
break
start = end - overlap
return chunkschunk_markdown.pychunk_markdown.pyC. Synthetic Data Generation
Then, we used a larger model (Gemma 3 27B via Ollama) to “read” each file and generate high-quality Question/Answer pairs. This is known as Synthetic Data Generation.
Prompt Strategy: Quality First
To avoid the “Garbage In, Garbage Out” trap, we didn’t just ask for data—we asked for Quality Control. We baked a filtering mechanism directly into the prompt by instructing the teacher model to grade its own homework:
PROMPT_TEMPLATE = """
You are an expert technical writer and educator.
Your task is to generate {num_pairs} high-quality question and answer pairs based ONLY on the provided text chunk.
For each pair, you must also assign a score (1-10) for:
- Accuracy: How efficiently does the answer address the question based on the text?
- Style: How natural, clear, and helpful is the phrasing?
...
"""generate_qa_with_score.pygenerate_qa_with_score.pyThis self-scoring mechanism is critical because it allows us to programmatically weed out low-quality generations in the next step.
This resulted in 779 total items, which were split into 701 training samples and 78 test samples (90/10 split):
{
"source": "blog/20251006-keeping-mcp-configs-in-sync.md",
"chunk_index": 2,
"question": "What file change does the launchd agent monitor?",
"answer": "The launchd agent watches Kilo Code's config file (`mcp_settings.json`) for changes.",
"accuracy": 10,
"style": 7
}data/train.jsonldata/train.jsonlD. Quality Filtering
“Garbage In, Garbage Out” is the golden rule of LLMs. A 12B model cannot magically become smarter than its training data.
As I mentioned above, I used a script to filter the generated data based on the self-evaluated scores. Any pair with a score below 6/10 was discarded, ensuring the model only learned from high-quality examples.
2. Training: Supervised Fine-Tuning (SFT)
We don’t just “show” the model the text; we treat it as an instruction-following task. This is known as Supervised Fine-Tuning (SFT).
The training script (src/train.py) formats each data pair into a conversation structure:
messages = [
{"role": "system", "content": "You are Mike 3.0..."},
{"role": "user", "content": "What file does Kilo Code save its settings to?"},
{"role": "assistant", "content": "Kilo saves its settings to `mcp_settings.json`."}
]The model is then trained to minimize the error (loss) when predicting the Assistant’s response, effectively learning to mimic my answers.
3. Training Configuration (src/lora_config.yaml)
I used Apple’s MLX framework, which allows fine-tuning LLMs directly on Apple Silicon. It creates “Adapters” — small add-on weights (only ~100MB) that sit on top of the base model.
# How we load the specific NumPy adapters
model, tokenizer = load(
"google/gemma-3-12b-it",
adapter_path="outputs/adapters.npz"
)src/inference.pysrc/inference.py# LoRA Configuration
model: "google/gemma-3-12b-it"
train: true
data: "data/mlx"
seed: 0
# LoRA Parameters
lora_parameters:
layer_keys:
[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
]
rank: 16
alpha: 32
dropout: 0.05
scale: 10.0
# Training Hyperparameters
batch_size: 2
iters: 1050
steps_per_eval: 100
save_every: 100
adapter_path: "outputs/adapters_phase.npz"
learning_rate: 1e-5
grad_checkpoint: truesrc/lora_config.yamlsrc/lora_config.yamlHere is the logic behind these settings, balancing theoretical best practices with hardware constraints:
- Rank (
16): The dimensionality of the adapter matrices that controls learning capacity. We kept this low to act as regularization, forcing the model to learn general patterns rather than simply memorizing the training data. - Alpha (
32): The scaling factor defining how strongly the adapter weights influence the base model. We followed the standard2x Rankrule to ensure the style transfer was robust without destabilizing the model. - Batch Size (
2): The number of training examples processed in parallel. Constrained by hardware, we kept this minimal to prevent Out-Of-Memory (OOM) errors on the MacBook’s Unified Memory. - Iterations (
1050): The total number of learning steps. This was calculated to achieve exactly 3 Epochs over our 700-item dataset. (700 items / 2 batch = 350 steps/epoch * 3) - Learning Rate (
1e-5): The step size for weight updates. We used a conservative rate to gently “nudge” the model towards the persona without destroying its pre-trained general knowledge (Catastrophic Forgetting). - Save Every (
100): The frequency of saving model checkpoints. This provided a safety net, allowing us to roll back if validation loss started to spike (Overfitting).
The Experiment Phases
I ran three distinct training phases to find the limits of Fine-Tuning.
Phase 1: Underfitting
I started with standard default settings to baseline the performance.
- Iterations: 200 (~0.6 Epochs)
- Rank: 16
Result: The model learned the Persona perfectly but suffered from Amnesia regarding specific facts.
Q: “What file does Kilo Code save its settings to according to the blog post: ‘Keeping MCP Configs in Sync’?”
A: “Kilo saves its settings to
~/.kilo.conf.” (Wrong)
Lesson: < 1 Epoch is enough for style, but insufficient for knowledge implementation.
Phase 2: Best Result
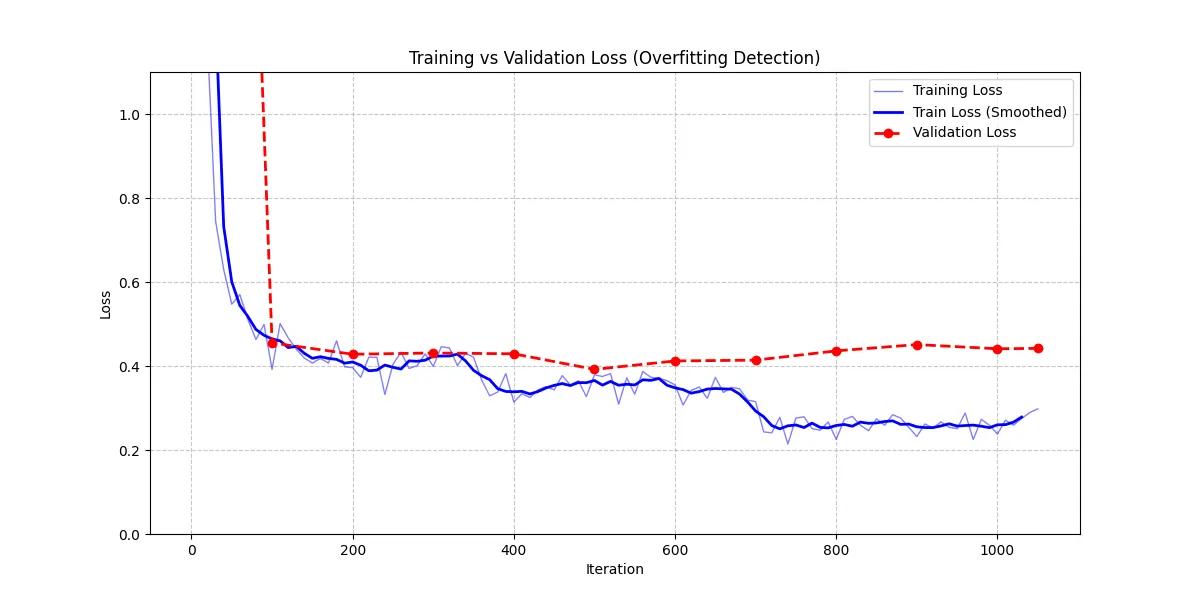
We increased training to 1050 iterations (exactly 3 Epochs). This forced the model to read the entire dataset three times.
- Iterations: 1050
- Rank: 16 (Regularized)
Result: Best result among the three attempts. As seen in the chart, the Validation Loss dropped consistently alongside the Training Loss for most of the run.
The trained model correctly answered specific technical questions in the dataset:
Q: “What file does Kilo Code save its settings to according to the blog post: ‘Keeping MCP Configs in Sync’?”
A: “Kilo saves its settings to
mcp_settings.json.” (Correct!)
However, despite this specific success, the model still struggled with broader knowledge retrieval. It consistently failed to answer questions that required synthesizing information from multiple posts—something the RAG model handled effortlessly by retrieving the exact source paragraphs.
Phase 3: Overfitting
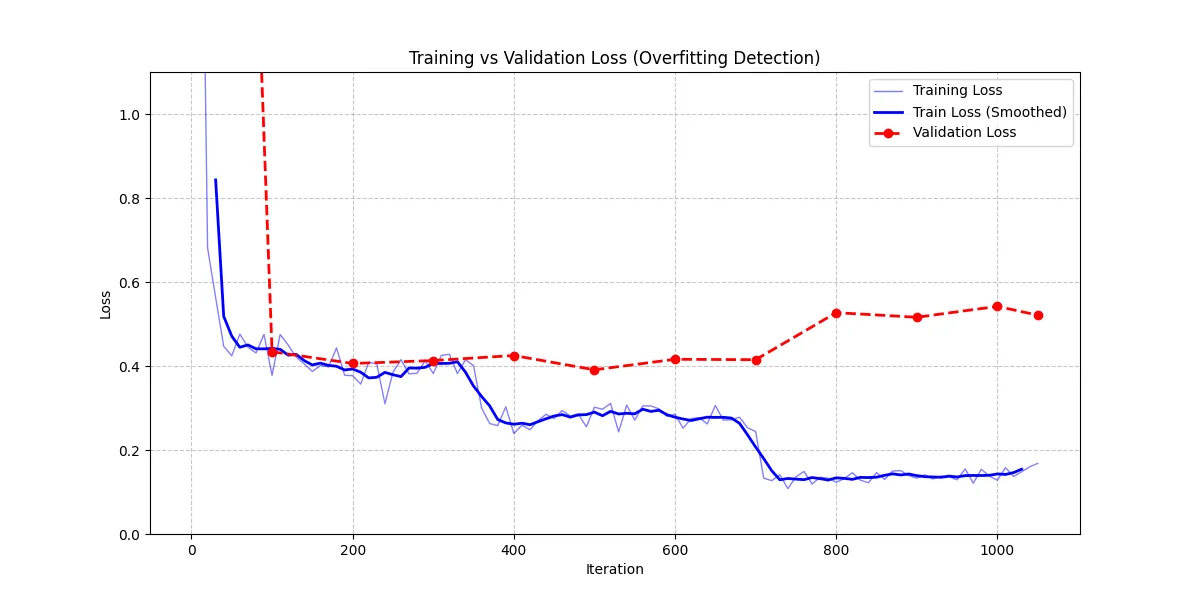
As an experiment, I increased the model’s “brain capacity” by quadrupling the Rank to 64 to see if it would yield further improvements.
- Iterations: 1050
- Rank: 64 (High Capacity)
Result: Regression (The U-Curve). This looks like it triggered classic Overfitting. As the chart shows, while the Training Loss (Blue) continued to plummet, the Validation Loss (Red) started to climb.
This should mean the model stopped learning the logic of the dataset and started memorizing specific phrasing.
Lesson: Capacity must match data scale. Increasing the Rank to 64 expanded the dimensionality of the trainable parameters, giving the model enough capacity to fit the noise in the small training set. The lower Rank (16) provided necessary regularization by constraining the optimization to a lower-dimensional subspace, forcing the model to capture only the most dominant, generalizable patterns.
The Verdict
I chose RAG for the purpose to teach Mike 3.0 model new facts.
Why LoRA Lost
While the LoRA experiment was technically impressive — proving that a 12B model can memorize a dataset (even obscure JSON filenames) with just 3 epochs — the maintenance burden is too high for a dynamic portfolio and the knowledge retention and accuracy are too low.
Future Consideration: The Hybrid Approach?
While it was hard to reliably learn new facts with LoRA, we could use it to shape the Persona of the bot in the future.
- LoRA for the Persona (Style, Tone, Safety).
- RAG for the Knowledge (Facts, Projects, Blog Posts).
This gives the best of both worlds: A bot that talks like me (LoRA) but reads my actual work (RAG).